$ psql postgres -c 'ALTER SYSTEM SET shared_preload_libraries TO auto_explain;' $ pg_ctl restart $ psql postgres -c 'ALTER SYSTEM SET auto_explain.log_min_duration TO 0;' $ psql postgres -c 'ALTER SYSTEM SET auto_explain.log_nested_statements TO on;' $ pg_ctl restart
接着,我们通过 psql 连接数据库,并创建如下函数。
1 2 3 4
CREATEOR REPLACE FUNCTION gibberish(int) RETURNS text LANGUAGESQLAS $_$ SELECTleft(string_agg(md5(random()::text),$$$$),$1) FROM generate_series(0,$1/32) $_$;
接着我们执行下面的查询命令。
1 2 3 4 5
SELECT x, md5(random()::text) as t11, gibberish(1500) as t12 FROM generate_series(1,20e6) f(x);
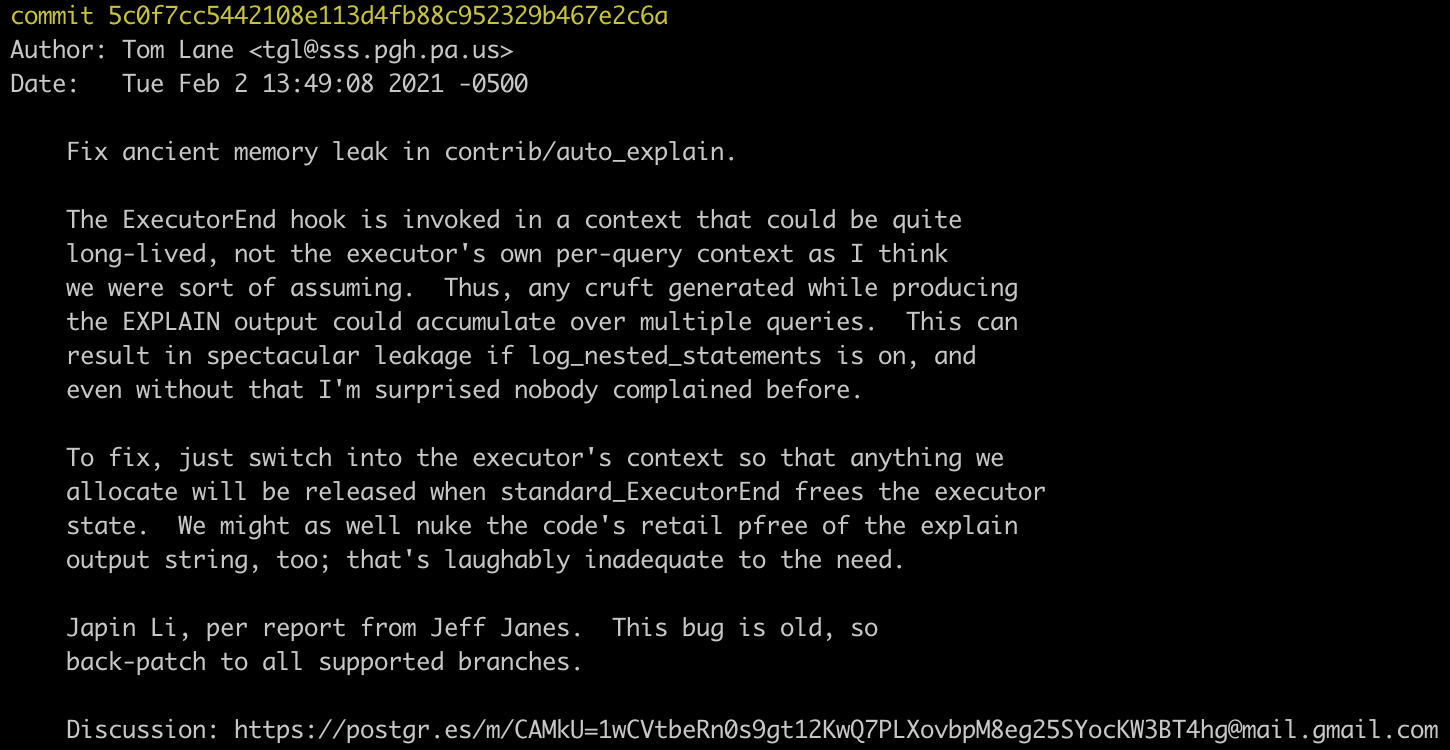
这个为了简化我省略了 CREATE TABLE j1 AS,因为这个不是内存泄露的关键。在执行上述命令的时候,我们可以通过 top -p <pid> 去观察,发现确实是内存一直在增长。
/* * Switch to context in which the fcache lives. This ensures that our * tuplestore etc will have sufficient lifetime. The sub-executor is * responsible for deleting per-tuple information. (XXX in the case of a * long-lived FmgrInfo, this policy represents more memory leakage, but * it's not entirely clear where to keep stuff instead.) */ oldcontext = MemoryContextSwitchTo(fcache->fcontext);
... }
这里可以看到,SQL function 的内存上下文可能会存在较长的生命周期,那么我们频繁的在该内存上下文上分配内存,就有可能导致内存泄露,而 explain_ExecutorEnd() 函数执行时的内存上下文就是在 SQL function 内存上下文中,对于相对简单的查询,可能这并不会有什么问题,这也是这个内存泄露没有被即使发现的原因,当我们执行上面的查询时这个问题就暴露出来了。
+ /* + * Make sure we operate in the per-query context, so any cruft will be + * discarded later during ExecutorEnd. + */ + oldcxt = MemoryContextSwitchTo(queryDesc->estate->es_query_cxt); + /* * Make sure stats accumulation is done. (Note: it's okay if several * levels of hook all do this.) @@ -424,9 +431,9 @@ explain_ExecutorEnd(QueryDesc *queryDesc) (errmsg("duration: %.3f ms plan:\n%s", msec, es->str->data), errhidestmt(true))); - - pfree(es->str->data); } + + MemoryContextSwitchTo(oldcxt); }