EXPLAIN SELECT*FROM flights WHERE actual_departure ISNULL;
1 2 3 4 5
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..4772.67 rows=16036 width=63) Filter: (actual_departure IS NULL) (2 rows)
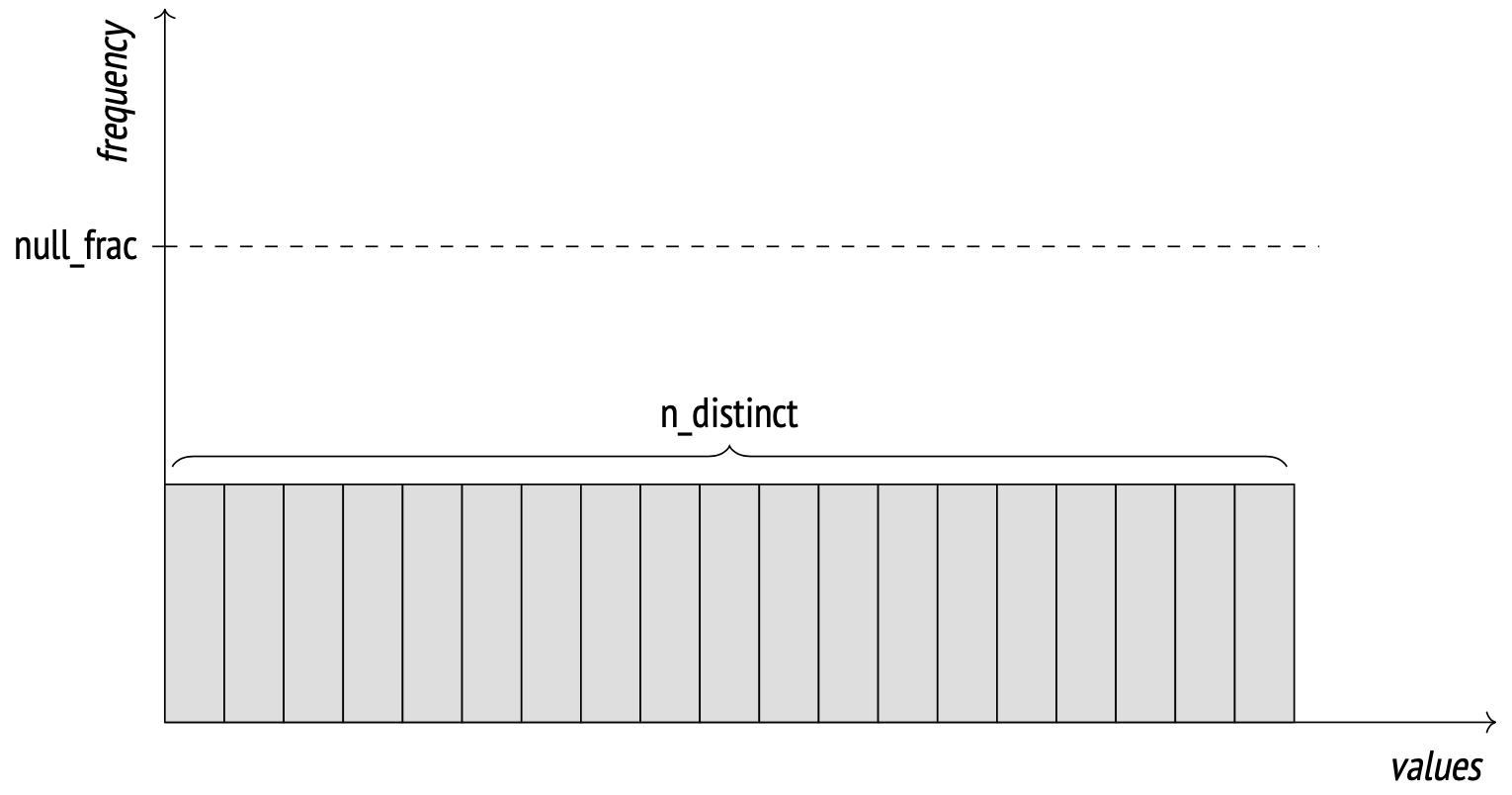
优化器将总行数乘以 NULL 值率得到估计的行数:
1 2 3 4 5
SELECT round(reltuples * s.null_frac) ASrows FROM pg_class JOIN pg_stats s ON s.tablename = relname WHERE s.tablename ='flights' AND s.attname ='actual_departure';
EXPLAIN SELECT*FROM flights WHERE departure_airport = ( SELECT airport_code FROM airports WHERE city ='Saint Petersburg' );
1 2 3 4 5 6 7 8
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=30.56..5340.40 rows=2066 width=63) Filter: (departure_airport = $0) InitPlan 1 (returns $0) −> Seq Scan on airports_data ml (cost=0.00..30.56 rows=1 wi... Filter: ((city −>> lang()) = 'Saint Petersburg'::text) (5 rows)
InitPlan 节点只执行一次,然后在主计划中使用该值替换 $0。
1 2 3 4 5
SELECT round(reltuples / s.n_distinct) ASrows FROM pg_class JOIN pg_stats s ON s.tablename = relname WHERE s.tablename ='flights' AND s.attname ='departure_airport';
SELECTmin(cnt), round(avg(cnt)) avg, max(cnt) FROM ( SELECT departure_airport, count(*) cnt FROM flights GROUPBY departure_airport ) t;
1 2 3 4
min | avg | max −−−−−+−−−−−−+−−−−−−− 113 | 2066 | 20875 (1 row)
最常见的值
为了提高非均匀分布的估计精度,分析器收集最常见值 (MCV, Most Common Calues) 及其频率的统计信息。这些信息存储在 pg_stats 的 most_common_vals 和 most_common_freqs 中。
以下是最常见飞机类型的此类统计数据示例:
1 2 3 4
SELECT most_common_vals AS mcv, left(most_common_freqs::text,60) ||'...'AS mcf FROM pg_stats WHERE tablename ='flights'AND attname ='aircraft_code' \gx
1 2 3
−[ RECORD 1 ]−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− mcv | {CN1,CR2,SU9,321,763,733,319,773} mcf | {0.2783,0.27473333,0.25816667,0.059233334,0.038533334,0.0370...
EXPLAIN SELECT*FROM flights WHERE aircraft_code ='733';
1 2 3 4 5
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..5309.84 rows=7957 width=63) Filter: (aircraft_code = '733'::bpchar) (2 rows)
1 2 3 4 5 6 7
SELECT round(reltuples * s.most_common_freqs[ array_position((s.most_common_vals::text::text[]),'733') ]) FROM pg_class JOIN pg_stats s ON s.tablename = relname WHERE s.tablename = 'flights' AND s.attname = 'aircraft_code';
1 2 3 4
round −−−−−−− 7957 (1 row)
这个估计值将接近 8263 的真实值。
MCV 列表也用于不等式的选择性估计:为了找到 column < value 的选择率,规划器在 most_common_vals 中搜索所有低于给定值的值,然后将它们从 most_common_freqs 中的频率相加。
EXPLAIN SELECT*FROM boarding_passes WHERE seat_no >'30C';
1 2 3 4 5
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on boarding_passes (cost=0.00..157353.30 rows=2943394 ... Filter: ((seat_no)::text > '30C'::text) (2 rows)
分割的座位号是专门选择在两个桶之间的边缘。
这个条件的选择率是 N / 桶数,其中 N 是具有匹配值的桶的数量(在分割的座位号的右侧)。请记住,直方图没有考虑最常见的值和未定义的值。让我们先看看匹配最常见值的分数:
1 2 3 4 5 6
SELECTsum(s.most_common_freqs[ array_position((s.most_common_vals::text::text[]),v) ]) FROM pg_stats s, unnest(s.most_common_vals::text::text[]) v WHERE s.tablename ='boarding_passes'AND s.attname ='seat_no' AND v >'30C';
1 2 3 4
sum −−−−−−−− 0.2127 (1 row)
现在让我们看看最常用值的频率(从直方图中排除):
1 2 3 4 5
SELECTsum(s.most_common_freqs[ array_position((s.most_common_vals::text::text[]),v) ]) FROM pg_stats s, unnest(s.most_common_vals::text::text[]) v WHERE s.tablename ='boarding_passes'AND s.attname ='seat_no';
1 2 3 4
sum −−−−−−−− 0.6762 (1 row)
seat_no 列中没有 NULL 值:
1 2 3
SELECT s.null_frac FROM pg_stats s WHERE s.tablename ='boarding_passes'AND s.attname ='seat_no';
1 2 3 4
null_frac −−−−−−−−−−− 0 (1 row)
区间正好涵盖 49 个桶(总共 100 个)。结果估计:
1 2 3 4 5
SELECT round( reltuples * ( 0.2127-- from most common values + (1-0.6762-0) * (49/100.0) -- from histogram )) FROM pg_class WHERE relname ='boarding_passes';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..6384.17 rows=1074 width=63) Filter: (EXTRACT(month FROM (scheduled_departure AT TIME ZONE ... (2 rows)
1 2
SELECT round(reltuples *0.005) FROM pg_class WHERE relname ='flights';
1 2 3 4
round −−−−−−− 1074 (1 row)
规划器甚至无法处理标准函数,而对我们来说,很明显 1 月份的航班比例将约为总航班的 1/12:
1 2 3 4 5
SELECTcount(*) AS total, count(*) FILTER (WHEREextract( monthFROM scheduled_departure ATTIME ZONE 'Europe/Moscow' ) =1) AS january FROM flights;
1 2 3 4
total | january −−−−−−−−+−−−−−−−−− 214867 | 16831 (1 row)
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..6384.17 rows=16222 width=63) Filter: (EXTRACT(month FROM (scheduled_departure AT TIME ZONE ... (2 rows)
DROP STATISTICS flights_expr; CREATE INDEX ON flights(extract( monthFROM scheduled_departure ATTIME ZONE 'Europe/Moscow' )); => ANALYZE flights; EXPLAIN SELECT*FROM flights WHEREextract( monthFROM scheduled_departure ATTIME ZONE 'Europe/Moscow' ) =1;
1 2 3 4 5 6 7
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on flights (cost=318.42..3235.96 rows=16774 wi... Recheck Cond: (EXTRACT(month FROM (scheduled_departure AT TIME... −> Bitmap Index Scan on flights_extract_idx (cost=0.00..314.2... Index Cond: (EXTRACT(month FROM (scheduled_departure AT TI... (4 rows)
表达式索引统计信息的存储方式与表统计信息相同。例如,这是不同值的数量:
1 2
SELECT n_distinct FROM pg_stats WHERE tablename ='flights_extract_idx';
1 2 3 4
n_distinct −−−−−−−−−−−− 12 (1 row)
在 PostgreSQL 11 及更高版本中,可以使用 ALTER INDEX 命令更改索引统计信息的准确性。您可能需要引用该表达式的列的名称。例如:
1 2
SELECT attname FROM pg_attribute WHERE attrelid ='flights_extract_idx'::regclass;
1 2 3 4
attname −−−−−−−−− extract (1 row)
1 2
ALTER INDEX flights_extract_idx ALTER COLUMN extract SET STATISTICS 42;
SELECTcount(*) FROM flights WHERE departure_airport ='SVO'AND aircraft_code ='733'
1 2 3 4
count −−−−−−− 2037 (1 row)
1 2
EXPLAIN SELECT*FROM flights WHERE departure_airport ='SVO'AND aircraft_code ='733';
1 2 3 4 5
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..5847.00 rows=733 width=63) Filter: ((departure_airport = 'SVO'::bpchar) AND (aircraft_cod... (2 rows)
我们可以使用多元 MCV 列表统计来改进估计:
1 2 3 4 5
CREATE STATISTICS flights_mcv(mcv) ON departure_airport, aircraft_code FROM flights; ANALYZE flights; EXPLAIN SELECT*FROM flights WHERE departure_airport ='SVO'AND aircraft_code ='733';
1 2 3 4 5
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..5847.00 rows=2077 width=63) Filter: ((departure_airport = 'SVO'::bpchar) AND (aircraft_cod... (2 rows)
现在系统表中有频率数据供规划器使用:
1 2 3 4 5 6
SELECTvalues, frequency FROM pg_statistic_ext stx JOIN pg_statistic_ext_data stxd ON stx.oid = stxd.stxoid, pg_mcv_list_items(stxdmcv) m WHERE stxname ='flights_mcv' ANDvalues='{SVO,773}';
1 2 3 4
values | frequency −−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−− {SVO,773} | 0.005733333333333333 (1 row)