PostgreSQL RelCache 和 SysCache 缓存
PostgreSQL 数据库大部分操作都依赖于系统表,因此为了加速访问,PostgreSQL 针对系统表提供了两种缓存:RelCache 和 SysCache。RelCache 和 SysCache 都是进程本地的,每个 backend 进程启动的时候都将创建自己的 RelCache 和 SysCache。本文将简要介绍一下这两类缓存。
- RelCache 用于缓存表的 RelationData 结构(关系描述符 -
reldesc),该结构由系统表中的元组构成。 - SysCache 用于缓存系统表的元组信息。
RelCache 缓存
RelCache 缓存的相关实现在 src/backend/utils/cache/relcache.c 文件中,文件 src/include/utils/relcache.h 则包含了相关函数的声明。
RelCache 的初始化可以分为三个阶段:
RelationCacheInitialize- 初始化reldesc缓存(创建一个空的哈希表缓存),此阶段由于事务子系统还没有运行,因此不能访问数据库。RelationCacheInitializePhase2- 该阶段主要是准备在启动时需要访问的共享系统表,此阶段至少需要加载pg_database、pg_authid、pg_auth_members和pg_shseclabel系统表。理想情况下,我们也需要加载其相应的索引。该函数尝试从共享的global/pg_internal.init文件中加载 RelCache 内容,如果失败的话,那么将通过formrdesc()函数为其创建一个预定义的reldesc。RelationCacheInitializePhase3- 当 CatCache 和事务系统正常运行,并且确定了数据库,则会调用该函数,在此之后,我们便可以从数据库的系统表中读取数据。
下图是整个 RelCache 初始化的流程。
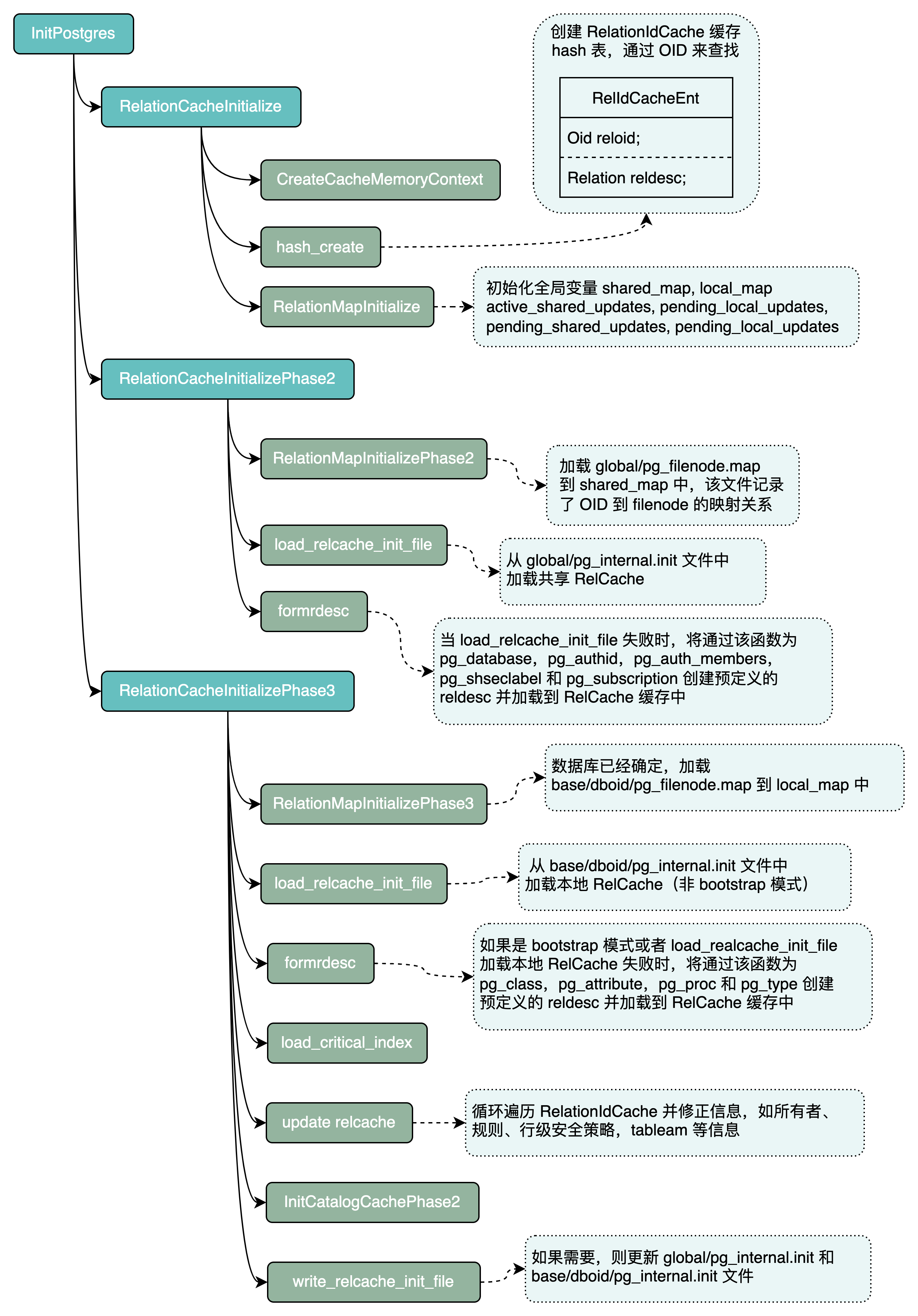
RelCache 初始化完成之后,我们便可以通过 RelationIdGetRelation() 函数获取 reldesc,在使用完之后,调用 RelationClose() 函数进行清理。
RelationIdGetRelation() 通过 OID 查找 reldesc,如果缓存中不存在则通过 BuildRelationDesc() 函数创建一个并加入到缓存,同时增加其引用计数。如下是其具体的实现:
1 | Relation |
关于 RelCache 缓存的梳理暂时收住,后续找时间在整理关于 RelCache 失效、同步等流程。
SysCache 缓存
SysCache 用于缓存系统表的元组信息,它的初始化相对简单,但是其使用要比 RelCache 稍微复杂一些,它们的源码主要集中在以下 4 个文件中:
src/backend/utils/cache/catcache.csrc/backend/utils/cache/syscache.csrc/include/utils/catcache.hsrc/include/utils/syscache.h
当然,还是从初始化开始,InitCatalogCache() 时 SysCache 初始化的入口,其实现如下所示:
1 | void |
其核心是 InitCatCache() 函数,该函数的主要任务就是分配内存,包括 CacheHdr、CatCache 和 buckets 的内存。
1 | CatCache * |
上述过程执行完成之后,其内存布局大致如下图所示:

上面的过程仅仅是分配内存和初始化缓存结构,在第一次使用该缓存时才会查询数据库以完成缓存的初始化。
接下来我们看看如何使用该缓存。PostgreSQL 提供了 SearchSysCache() 来查询缓存,它是对 SearchCatCache() 的封装,如下所示:
1 | HeapTuple |
1 | HeapTuple |
类似的还有 SearchSysCache1()、SearchSysCache2()、SearchSysCache3() 和 SearchSysCache4(),它们将检查键的数量是否与其相等。它们最终会调用 SearchCatCacheInternal() 和 SearchCatCacheMiss() 函数,其调用关系如下图所示:
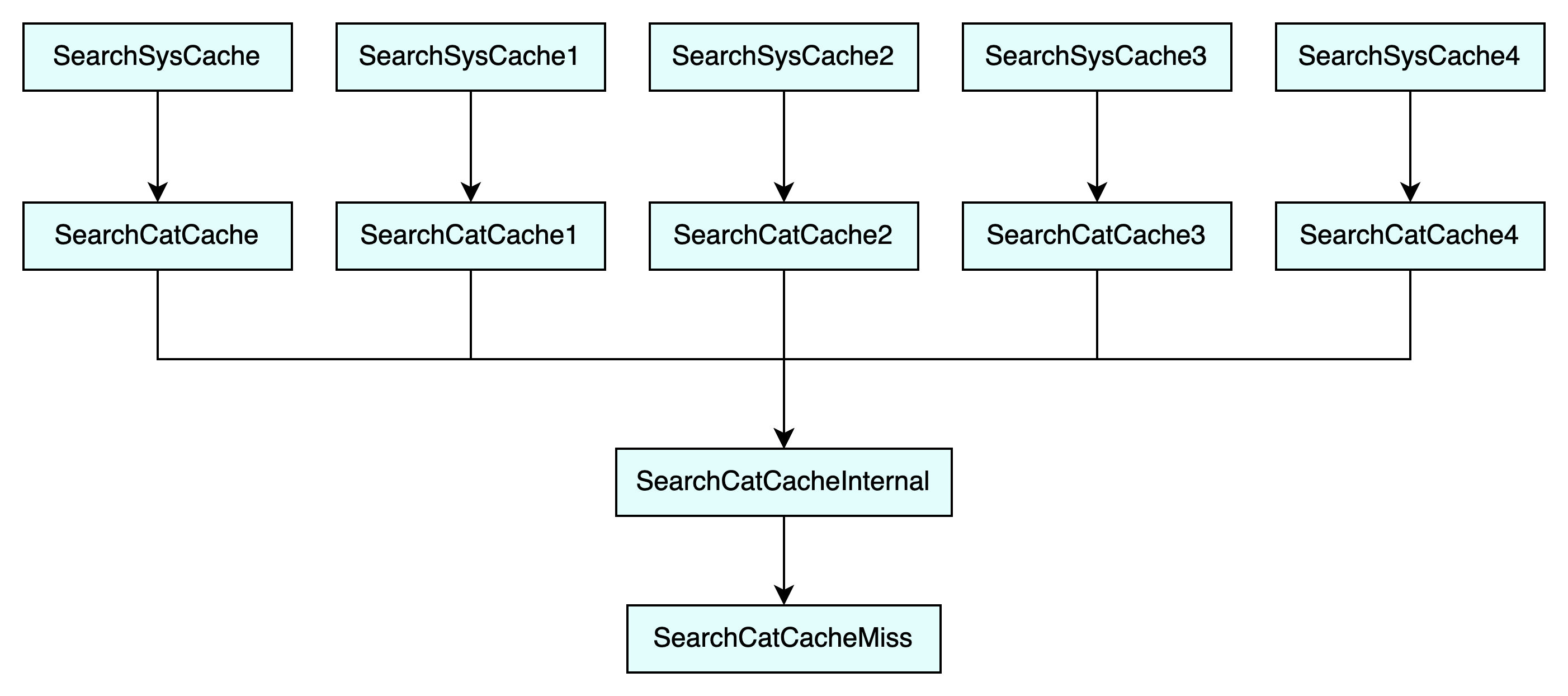
不难看出其核心就在 SearchCatCacheMiss() 函数中,当缓存未命中时,它将读取表元组信息并将其加入到缓存中。
1 | static pg_noinline HeapTuple |
CatalogCacheCreateEntry() 负责创建一个 CatCTup 结构并将其加入到 cache->cc_bucket,其中 hashIndex 用于索引 cache->cc_bucket,下面是该函数主要流程。
1 | static CatCTup * |
当我们通过 SearchSysCache() 函数获取信息时,元组信息就会以 CatCTup 的形式缓存起来,其内存布局如下所示:
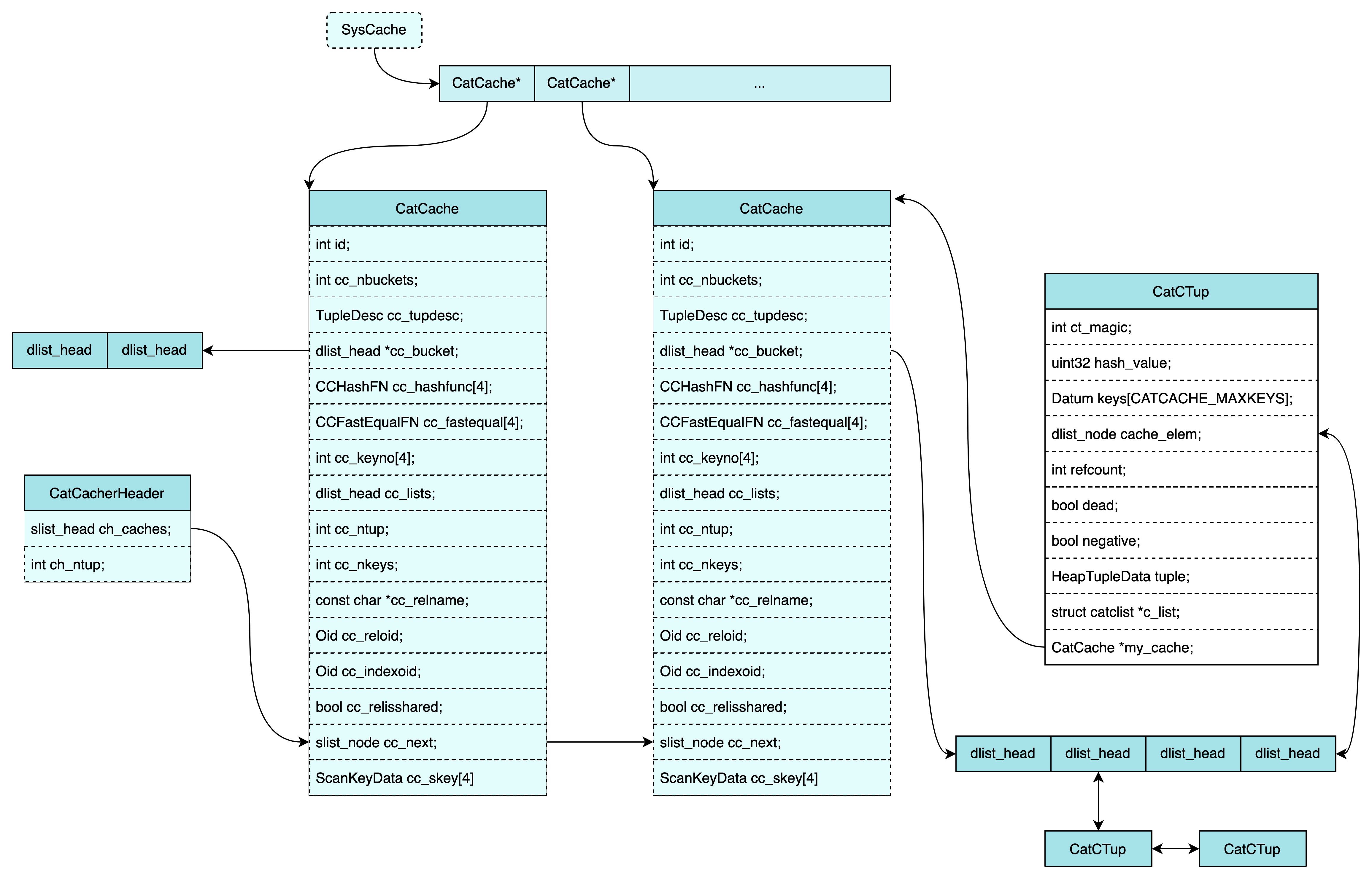
关于 SysCache 的分析暂时就到这里,这里面还有很多内容,如部分搜索(CatCTup 中 struct catclist *c_list 的处理,即 N 个键中前 K 个键的缓存处理)、缓存同步、失效等。
孔子见死麟,哭之不置。
弟子谋所以慰之者,乃编钱挂牛体,告曰:“麟已活矣。”孔子观之曰:“这明明是一只村牛,不过多得几个钱耳。”