现代的 GCC 和 Clang 编译器都提供了一种高级优化技术 - 链接时优化(L ink-T ime O ptimization, LTO),它允许编译器在链接时对整个程序进行全局分析和优化,而不是仅限于单个编译单元(源文件)。
LTO 是什么 LTO 是一种跨模块优化技术,通过在编译和链接阶段共享中间表示(I ntermediate R epresentation, IR)来实现全局优化。通常,传统编译过程将每个源文件独立编译为目标代码(object code),然后在链接阶段将这些目标代码组合成可执行文件。这种方式限制了优化范围,因为编译器无法看到整个程序的上下文。
LTO 改变了这一流程:
在编译阶段(gcc -c -flto 或 clang -flto),源代码被编译为包含(IR)的目标文件,而不是直接生成机器码。
在链接阶段(通过 ld 或其他链接工具),编译器加载所有 IR,合并成一个全局的 IR,对整个程序进行优化,然后生成最终的可执行文件。
LTO 的作用 LTO 的主要作用是通过全局分析和优化,从而提升程序性能和减小代码体积。具体作用包括:
跨模块内联: LTO 允许编译器将一个模块(文件)中的函数内联到另一个模块的调用点,即使这些函数在不同原文件中定义。这可以减少函数调用的开销,提供执行效率。全局优化: LTO 可以分析整个程序的调用图和数据流,从而进行更激进的优化,例如:
死代码消除(Dead Code Elimination): 移出未被使用的函数或代码块。常量传播(Constant Propagation): 将常量值传播到整个程序,减少运行时计算。常量折叠(Constant Folding): 编译器对涉及常量的表达式进行预计算,提前得出结果,并用结果替换表达式,减少运行时计算量。循环优化(Loop Optimization): 合并或重构模块的循环结构。
代码体积优化: 通过移出冗余代码、合并重复函数等,LTO 可以显著减小生成的可执行文件大小。性能提升: 由于全局分析,LTO 可以生成更高效的机器码,尤其在复杂程序中,性能提升可能达到 5-20%(具体效果取决于代码结构和优化场景)。支持现代编译器特性: LTO 是许多高级优化(如反馈引导优化 FDO、自动向量化)的必要条件,因为这些优化需要全局信息。
示例 跨模块内联 LTO 允许编译器将一个模块(源文件)中的函数内联到另一个模块的调用点,即使这些函数定义在不同文件中。这可以减少函数调用开销(如栈帧分配、参数传递),提高性能。
file1.c 1 2 3 4 5 int square (int x) { return x * x; }
file2.c 1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> extern int square (int x) ;int main (void ) { int num = 5 ; int res = square(num); printf ("square(%d) = %d\n" , num, res); return 0 ; }
下面是不启用 LTO 时,生成的目标代码中 main() 函数会通过调用指令 call 调用 square() 函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ gcc -O3 -o non-lto file1.c file2.c $ objdump -d non-lto | grep -A 17 '<main>:' 0000000000001060 <main>: 1060: f3 0f 1e fa endbr64 1064: 48 83 ec 08 sub $0x8,%rsp 1068: bf 05 00 00 00 mov $0x5,%edi 106d: e8 1e 01 00 00 call 1190 <square> 1072: ba 05 00 00 00 mov $0x5,%edx 1077: bf 02 00 00 00 mov $0x2,%edi 107c: 48 8d 35 81 0f 00 00 lea 0xf81(%rip),%rsi # 2004 <_IO_stdin_used+0x4> 1083: 89 c1 mov %eax,%ecx 1085: 31 c0 xor %eax,%eax 1087: e8 c4 ff ff ff call 1050 <__printf_chk@plt> 108c: 31 c0 xor %eax,%eax 108e: 48 83 c4 08 add $0x8,%rsp 1092: c3 ret 1093: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1) 109a: 00 00 00 109d: 0f 1f 00 nopl (%rax) $ objdump -d non-lto | grep -A 5 '<square>:' 0000000000001190 <square>: 1190: f3 0f 1e fa endbr64 1194: 0f af ff imul %edi,%edi 1197: 89 f8 mov %edi,%eax 1199: c3 ret
可以看到上面的第 7 行中调用了 square() 函数。当启用 LTO 时,它将分析整个程序,并注意到 square() 函数的定义和调用点。由于 square() 是一个简单函数,LTO 可能选择将其内联到 main() 函数中,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ gcc -O3 -flto -o lto file1.c file2.c $ objdump -d lto | grep -A 13 '<main>:' 0000000000001060 <main>: 1060: f3 0f 1e fa endbr64 1064: 48 83 ec 08 sub $0x8,%rsp 1068: b9 19 00 00 00 mov $0x19,%ecx 106d: ba 05 00 00 00 mov $0x5,%edx 1072: 31 c0 xor %eax,%eax 1074: 48 8d 35 89 0f 00 00 lea 0xf89(%rip),%rsi # 2004 <_IO_stdin_used+0x4> 107b: bf 02 00 00 00 mov $0x2,%edi 1080: e8 cb ff ff ff call 1050 <__printf_chk@plt> 1085: 31 c0 xor %eax,%eax 1087: 48 83 c4 08 add $0x8,%rsp 108b: c3 ret 108c: 0f 1f 40 00 nopl 0x0(%rax)
从上面的汇编代码可以看到,当启用 LTO 之后,函数 square() 的调用被优化了,取而代之的是第 6 行的立即数 0x19(见后文的常量传播 & 常量折叠 )。这同样使得二进制程序体积也变小了。
1 2 3 $ ls -al *lto-rwxrwxr-x 1 japin japin 15936 Apr 27 18:01 lto -rwxrwxr-x 1 japin japin 16032 Apr 27 17:48 non-lto
在这个例子中,LTO 消除了函数调用的开销(call 和 ret 指令),同时减少了栈操作(参数传递),使得代码更紧凑、执行速度更快。
死代码消除 LTO 可以识别并移除程序中未被使用的函数或代码块(死代码),减少可执行文件大小并提高性能。
file1.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> int unused_func (void ) { printf ("this function is not ussed\n" ); return 1 ; } int used_func (int x) { printf ("This function is used with argument %d\n" , x); return x * x; }
file2.c 1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> extern int used_func (int x) ;int main (void ) { int num = 5 ; int res = used_func(num); printf ("used_func(%d) = %d\n" , num, res); return 0 ; }
同样,我们先开不启用 LTO 时的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 $ gcc -O3 -o non-lto file1.c file2.c $ objdump -d non-lto | grep -A 17 '<main>:' 0000000000001080 <main>: 1080: f3 0f 1e fa endbr64 1084: 48 83 ec 08 sub $0x8,%rsp 1088: bf 05 00 00 00 mov $0x5,%edi 108d: e8 3e 01 00 00 call 11d0 <used_func> 1092: ba 05 00 00 00 mov $0x5,%edx 1097: bf 02 00 00 00 mov $0x2,%edi 109c: 48 8d 35 7c 0f 00 00 lea 0xf7c(%rip),%rsi # 201f <_IO_stdin_used+0x1f> 10a3: 89 c1 mov %eax,%ecx 10a5: 31 c0 xor %eax,%eax 10a7: e8 c4 ff ff ff call 1070 <__printf_chk@plt> 10ac: 31 c0 xor %eax,%eax 10ae: 48 83 c4 08 add $0x8,%rsp 10b2: c3 ret 10b3: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1) 10ba: 00 00 00 10bd: 0f 1f 00 nopl (%rax) $ objdump -d non-lto | grep -A 13 '<used_func>:' 00000000000011d0 <used_func>: 11d0: f3 0f 1e fa endbr64 11d4: 53 push %rbx 11d5: 89 fb mov %edi,%ebx 11d7: 89 fa mov %edi,%edx 11d9: 48 8d 35 58 0e 00 00 lea 0xe58(%rip),%rsi # 2038 <_IO_stdin_used+0x38> 11e0: 0f af db imul %ebx,%ebx 11e3: bf 02 00 00 00 mov $0x2,%edi 11e8: 31 c0 xor %eax,%eax 11ea: e8 81 fe ff ff call 1070 <__printf_chk@plt> 11ef: 89 d8 mov %ebx,%eax 11f1: 5b pop %rbx 11f2: c3 ret $ objdump -d non-lto | grep -A 9 '<unused_func>:' 00000000000011b0 <unused_func>: 11b0: f3 0f 1e fa endbr64 11b4: 48 83 ec 08 sub $0x8,%rsp 11b8: 48 8d 3d 45 0e 00 00 lea 0xe45(%rip),%rdi # 2004 <_IO_stdin_used+0x4> 11bf: e8 9c fe ff ff call 1060 <puts@plt> 11c4: b8 01 00 00 00 mov $0x1,%eax 11c9: 48 83 c4 08 add $0x8,%rsp 11cd: c3 ret 11ce: 66 90 xchg %ax,%ax
编译器在编译器 file1.c 时,会将 unused_function 和 used_function 都编译为目标代码。链接器则保留了 unused_func() 函数的实现,从而导致生成的可执行文件中包含了其代码,增加了二进制的大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ gcc -O3 -flto -o lto file1.c file2.c $ objdump -d lto | grep -A 20 '<main>:' 0000000000001060 <main>: 1060: f3 0f 1e fa endbr64 1064: 48 83 ec 08 sub $0x8,%rsp 1068: ba 05 00 00 00 mov $0x5,%edx 106d: bf 02 00 00 00 mov $0x2,%edi 1072: 31 c0 xor %eax,%eax 1074: 48 8d 35 8d 0f 00 00 lea 0xf8d(%rip),%rsi # 2008 <_IO_stdin_used+0x8> 107b: e8 d0 ff ff ff call 1050 <__printf_chk@plt> 1080: b9 19 00 00 00 mov $0x19,%ecx 1085: ba 05 00 00 00 mov $0x5,%edx 108a: 31 c0 xor %eax,%eax 108c: 48 8d 35 9d 0f 00 00 lea 0xf9d(%rip),%rsi # 2030 <_IO_stdin_used+0x30> 1093: bf 02 00 00 00 mov $0x2,%edi 1098: e8 b3 ff ff ff call 1050 <__printf_chk@plt> 109d: 31 c0 xor %eax,%eax 109f: 48 83 c4 08 add $0x8,%rsp 10a3: c3 ret 10a4: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1) 10ab: 00 00 00 10ae: 66 90 xchg %ax,%ax $ objdump -d lto | grep -A 20 '<used_func>:' $ objdump -d lto | grep -A 20 '<unused_func>:'
从上面可以看到 unsed_func() 函数被 LTO 完全移除(注意,由于 LTO 的跨模块内联优化,我们同样无法看到 used_func() 函数的实现,因为它已经内联到 main() 中)。
同样的,LTO 优化的二进制相对来说要小一些。
1 2 3 $ ls -al *lto-rwxrwxr-x 1 japin japin 15936 Apr 27 18:30 lto -rwxrwxr-x 1 japin japin 16104 Apr 27 18:22 non-lto
常量传播 & 常量折叠 常量传播和常量折叠都是编译器优化技术,它们都涉及到在编译时处理常量,但目标和实现方式有所不同。下表给出了这两种优化技术的区别:
特征
常量传播 (Constant Propagation)
常量折叠 (Constant Folding)
目标
将已知常量的值传播到其他使用这些值的地方。
在编译时计算出完全由常量组成的表达式的值。
操作对象
变量和表达式中使用了已知常量值的部分。
完全由常量组成的表达式。
发生时机
当编译器确定变量或表达式在某点是常量时进行替换。
当编译器识别出表达式的所有操作数都是常量时进行计算。
条件
需要编译器能够确定某个变量的值是常量。
表达式的所有操作数必须是常量。
效果
减少变量读取,为常量折叠创造条件。
减少运行时计算,减小代码大小。
依赖性
常量传播可以为常量折叠创造机会。
常量折叠通常发生在常量传播之后。
假设我们有如下代码:
1 2 3 4 5 6 7 8 9 int main (void ) { int x = 10 ; int y = x * 2 ; int z = y + 5 ; printf ("%d\n" , z); return 0 ; }
经过常量传播之后,代码可能变成如下形式:
1 2 3 4 5 6 7 8 9 int main (void ) { int x = 10 ; int y = 10 * 2 ; int z = 20 + 5 ; printf ("%d\n" , z); return 0 ; }
上述代码再经过常量折叠之后,可能变为如下形式:
1 2 3 4 5 6 7 8 9 int main (void ) { int x = 10 ; int y = 20 ; int z = 25 ; printf ("%d\n" , z); return 0 ; }
总而言之,常量传播 是识别 和传递 常量值的过程,而常量折叠 是计算 由常量组成的表达式的值的过程。它们通常一起工作,互相促进,以达到更好的代码优化效果。
其实在上面跨模块内联和死代码消除示例中已经用到了常量传播和常量折叠。我们以下的示例来对其进行解释。
file1.c 1 2 3 4 5 int get_constant () { return 10 ; }
file2.c 1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> extern int get_constant () ;int main (void ) { int value = get_constant(); int result = value * 2 ; printf ("result = %d\n" , result); return 0 ; }
当不启用 LTO 时,编译器无法确定 get_constant() 函数的返回值,因此会生成调用 get_constant() 的代码并在运行时计算 value * 2。如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ gcc -O3 -o non-lto file1.c file2.c $ objdump -d non-lto | grep -A 14 '<main>:' 0000000000001060 <main>: 1060: f3 0f 1e fa endbr64 1064: 48 83 ec 08 sub $0x8,%rsp 1068: 31 c0 xor %eax,%eax 106a: e8 11 01 00 00 call 1180 <get_constant> 106f: 48 8d 35 8e 0f 00 00 lea 0xf8e(%rip),%rsi # 2004 <_IO_stdin_used+0x4> 1076: bf 02 00 00 00 mov $0x2,%edi 107b: 8d 14 00 lea (%rax,%rax,1),%edx 107e: 31 c0 xor %eax,%eax 1080: e8 cb ff ff ff call 1050 <__printf_chk@plt> 1085: 31 c0 xor %eax,%eax 1087: 48 83 c4 08 add $0x8,%rsp 108b: c3 ret 108c: 0f 1f 40 00 nopl 0x0(%rax) $ objdump -d non-lto | grep -A 4 '<get_constant>:' 0000000000001180 <get_constant>: 1180: f3 0f 1e fa endbr64 1184: b8 0a 00 00 00 mov $0xa,%eax 1189: c3 ret
当启用 LTO 时,LTO 将分析整个程序,其流程大致如下:
跨模块内联: LTO 发现 get_constant() 是一个简单函数,并且返回固定值 10,因此将其内联到 main() 函数,代码逻辑变为: 1 2 3 int value = 10; int result = value * 2; printf("result = %d\n", result);
常量传播: LTO 分析发现 value 的值始终是 10,因此将所有使用 value 的地方替换为 10,代码逻辑变为: 1 2 3 int value = 1; int result = 10 * 2; printf("result = %d\n", result);
常量折叠: LTO 发现表达式 10 * 2 是常量表达式,因此可以在编译时计算,使用计算后额结果 20 替代,代码逻辑为: 1 2 3 int value = 1; int result = 20; printf("result = %d\n", result);
死代码消除: LTO 发现 value = 10 的赋值不再被使用(因为 value 已经被替换为常量 10,其后续没有其他引用),因此删除了 value 的定义,代码进一步简化: 1 2 int result = 20; printf("result = %d\n", result);
get_constant() 函数实现,进一步减小了代码体积。
下面是开启 LTO 优化之后,程序的汇编代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ gcc -O3 -flto -o lto file1.c file2.c $ objdump -d lto | grep -A 13 '<main>:' 0000000000001060 <main>: 1060: f3 0f 1e fa endbr64 1064: 48 83 ec 08 sub $0x8,%rsp 1068: ba 14 00 00 00 mov $0x14,%edx ; 直接将立即数 20 作为 printf 的参数传入 106d: bf 02 00 00 00 mov $0x2,%edi 1072: 31 c0 xor %eax,%eax 1074: 48 8d 35 89 0f 00 00 lea 0xf89(%rip),%rsi # 2004 <_IO_stdin_used+0x4> 107b: e8 d0 ff ff ff call 1050 <__printf_chk@plt> 1080: 31 c0 xor %eax,%eax 1082: 48 83 c4 08 add $0x8,%rsp 1086: c3 ret 1087: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1) 108e: 00 00 $ objdump -d lto | grep -A 4 '<get_constant>:'
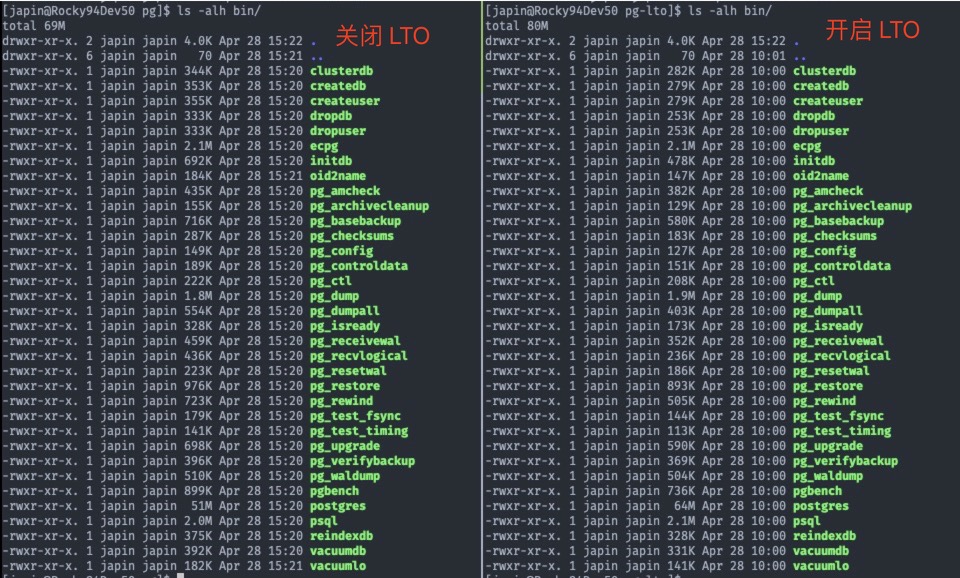
下面是 PostgreSQL 在关闭 LTO 与关闭 LTO 直接的二进制程序大小的对比,可以看到在开启 LTO 后,大部分程序的体积都变小了,但是也存在几个程序体积膨胀了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 program: 1 - size(lto) / size(non-lto) bin/clusterdb: 0.18129679783335984 bin/createdb: 0.20910541714691022 bin/createuser: 0.2142070969446157 bin/dropdb: 0.23976896527435376 bin/dropuser: 0.2393879565646594 bin/ecpg: 0.007508113848132658 bin/initdb: 0.30928556908273663 bin/oid2name: 0.20247406903587828 bin/pg_amcheck: 0.12143820224719104 bin/pg_archivecleanup: 0.1710194615307048 bin/pg_basebackup: 0.1902272950470849 bin/pg_checksums: 0.3643172286072226 bin/pg_config: 0.14524698826871485 bin/pg_controldata: 0.20343056015909844 bin/pg_ctl: 0.06443080829454084 bin/pg_dump: -0.060014953670324944 bin/pg_dumpall: 0.27333022875125246 bin/pg_isready: 0.4728067451692264 bin/pg_receivewal: 0.23297228144989335 bin/pg_recvlogical: 0.46053221037541436 bin/pg_resetwal: 0.1672635348641247 bin/pg_restore: 0.08486154043275618 bin/pg_rewind: 0.3014151810328983 bin/pg_test_fsync: 0.19472740786079656 bin/pg_test_timing: 0.19667482206405695 bin/pg_upgrade: 0.15564912595047986 bin/pg_verifybackup: 0.06807585934413274 bin/pg_waldump: 0.010651850260156914 bin/pgbench: 0.18221642764015644 bin/postgres: -0.26138824909773395 bin/psql: -0.07266102197991042 bin/reindexdb: 0.12694440969181364 bin/vacuumdb: 0.15794195040267922 bin/vacuumlo: 0.2265383293227914
其中,pg_dump,postgres 和 psql 三个程序出现了膨胀,可能的原因:
pg_dump 和 postgres: 这两个程序都非常庞大和复杂,包含大量函数和逻辑。LTO 在尝试进行跨模块优化和函数内联时,可能因为需要内联较大的函数或者生成更多特殊化的代码,导致最终的二进制文件体积略微增加。psql: 作为一个交互式命令行工具,psql 依赖于 libpq 库进行数据库连接和交互。LTO 对 libpq 的优化以及 psql 自身代码的优化方式,可能导致最终 psql 的二进制文件略微增大。
总结 本文简要介绍了编译器优化中的 LTO 优化,并以其中常见的几种优化手段加以说明,从而方便理解。编译器优化还有很多其他优化手段,比如循环展开(Loop Unroll)、循环不变量外提(Loop Invariant Code Motion)、尾调用优化(Tail Call Optimization)等,感兴趣的朋友可以参考这里 。
参考 [1] https://zhuanlan.zhihu.com/p/617485437 https://oi-wiki.org/lang/optimizations/
笑林广记 - 金漆盒
一近视出门,见街头牛屎一大堆,认为路人遗下的盒子,遂用双手去捧。