构建简单的数据库
使用 C 语言从头实现类 sqlite 数据库
01 - 简介与 REPL 解释器
作为一名 WEB 开发者,我几乎每天都在使用关系型数据库,但是它对于我来说就是一个黑盒子。我总是有如下疑问:
- 数据在磁盘和内存上的存储格式是怎样的?
- 何时将数据从内存写入磁盘?
- 为什么每个表只能有一个主键?
- 事务回滚是如何进行的?
- 数据库索引的格式是什么样的?
- 数据库何时会进行全表扫描?全表扫描是如何工作的?
- PREPARED 语句是以什么格式保存的?
简言之,就是数据库到底是如何工作的?
为了弄明白数据库是如何工作的,我以 sqlite 数据库为原型,从头实现了一个关系型数据库。Sqlite 数据库的特性相对于 MySQL 和 PostgreSQL 来说要少一些,但是我可以更好的理解数据库的原理。整个数据库的源码均存放在一个源文件中。
Sqlite 数据库
Sqlite 官网有许多关于其内部结构的文档,同时,我也参考了 SQLite Database System: Design and Implementation 一书。
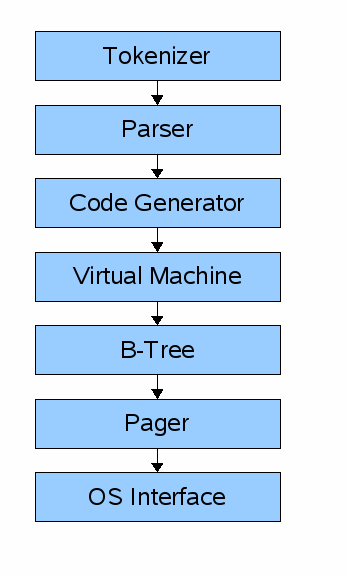 |
为了获取查询结果或者修改数据,查询语句将经历一些列组件的处理。其中前端 (front-end) 主要由以下三个部分组成:
- tokenizer
- parser
- code generator
前端的输入是一个 SQL 查询语句,它的输出则是 sqlite 的虚拟机字节码(本质上就是一个已经编译好的可以被数据库执行的程序)。
而后端 (back-end) 则由以下四个部分组成:
- virtual machine
- B-tree
- pager
- os interface
后端虚拟机 (virtual machine) 将前端代码生成器 (code generator) 产生的字节码作为执行的指令。它将指导虚拟机如何在表和索引上进行操作,其中,表和索引均存储 B-tree 数据结构中。虚拟机的本质就是针对字节码指令的一个大的 switch 语句。
B-tree 由许多节点组成,每个节点都包含一个页面的长度。我们通过向页面管理器 (pager) 发送命令即可以从磁盘读取页面或者写入页面到磁盘。
页面管理器负责读写页面数据。它负责维护读写数据文件的位置,同时,在内存中维护一个最近访问的页面缓存信息,并决定哪些页面需要被回写到磁盘。
操作信息接口 (os interface) 决定了 sqlite 可以在哪些操作系统上编译运行。在本文中,我将不会支持多平台。
简单的 REPL
当你在命令行启动 sqlite 时,它从一个 读取-执行-打印 (read-execute-print) 循环开始。
~ sqlite3
SQLite version 3.16.0 2016-11-04 19:09:39
Enter ".help" for useage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> create table users (id int, username varchar(255), email varchar(255));
sqlite> .tables
users
sqlite> .exit
~
为了实现上述功能,我们的主函数需要一个无限循环来打印提示符,获取用户命令,接着执行命令:
int
main(int argc, char *argv[])
{
input_buffer_t *input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
return 0;
}
我们定义 InputBuffer 结构作为对用户交互状态的一个包装,它内部使用了 getline()。(后面将详细介绍)
struct InputBuffer_t
{
char *buffer;
size_t buffer_length;
ssize_t input_length;
};
typedef struct InputBuffer_t InputBuffer;
InputBuffer *
new_input_buffer()
{
InputBuffer *input_buffer = (InputBuffer *) malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
接着,我们将在读取用户输入之前使用 print_prompt() 函数为用户打印提示符。
void
print_prompt()
{
printf("db > ");
}
我们将使用 getline() 函数来读取用户的输入。
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
lineptr: 指向存放用户输入数据的指针。n: 用户输入数据的实际长度。stream: 需要读取输入的输入流。我们将把该参数设置为标准输入流。return value: 读取的字节数,它可能小于缓冲区的大小。
我们告诉 getline 函数将读取的数据存放入 input_buffer->buffer 中,而分配的缓冲区的大小则存放入 input_buffer->buffer_length 中。最后,实际读取的长度则保存在 input_buffer->input_length 中。
buffer 被初始化为空 (NULL),因此 getline 函数可以分配足够的空间来保存用户数据并将 buffer 指向这一内存区域。
void
read_input(InputBuffer *input_buffer)
{
ssize_t bytes_read;
bytes_read = getline(&input_buffer->buffer,
&input_buffer->buffer_length,
stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
/* Ignore trailing newline */
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
最后,我们解析并执行命令。现在我们仅支持一个命令:.exit,该命令意味着结束程序。否则,我们就输出一个错误信息并继续循环。
if (strcmp(input_buffer->buffer, ".exit") == 0) {
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
现在,我们编译并测试一下。
~ ./db
db > .tables
Unrecognized command '.tables'.
db > .exit
译者注: @cstack 是在 Mac 平台完成了本项目,而我是在 Ubuntu 平台上完成的,因此源码可能有所不同。