构建简单的数据库
使用 C 语言从头实现类 sqlite 数据库
07 - B-Tree 结构
SQLite 使用 B-Tree 结构来组织表和索引,因此它是其核心思想。本文仅对该数据结构做介绍,因此不会涉及到任何代码。
为什么 tree 是数据库的良好数据结构呢?
- 查询特定的值非常快(对数时间内完成)
- 插入/删除已经找到的值非常快(持续的重新平衡)
- 遍历一系列的值非常快(与 hash map 有所不同)
B-Tree 与二叉树不同(“B” 可能代表发明者的名字,也可能是平衡 “balanced” 的意思)。下面是一个 B-Tree 的示例:
 |
与二叉树不同,每个 B-Tree 的节点可以包含 2 个以上的子节点。每个节点可以至多包含 m 个子节点,其中 m 被称为树的 “order”。为了尽可能的保持树的平衡,我们还需要保证节点必须至少包含 m/2 个子节点(向上取整)。
例外情况:
- 叶子节点没有子节点
- 根节点的子节点个数可以少于 m 个,但是必须至少含有 2 个子节点
- 如果根节点也是叶子节点(即只有一个节点),那么它拥有 0 个子节点
上图是一棵 B-Tree,SQLite 使用它来存储索引。为了存储表,SQLite 使用了一种称为 B+ tree 的变体。
| B-tree | B+ tree | |
|---|---|---|
| Pronounced | “Bee Tree” | “Bee Plus Tree” |
| Used to stores | Indexes | Tables |
| Internal nodes store keys | Yes | Yes |
| Internal nodes store values | Yes | No |
| Number of children per node | Less | More |
| Internal nodes vs. leaf nodes | Same structure | Different structure |
在我们实现索引之前,我们将只讨论 B+ tree,但是我们将其称为 B-tree 或者 btree。
拥有子子节点的节点被称为内部节点(”internal” nodes)。内部节点和叶子节点是不同的:
| For an order-m tree… | Internal Node | Leaf Node |
|---|---|---|
| Stores | keys and pointers to children | Keys and values |
| Number of keys | up to m-1 | as many as will fit |
| Number of pointers | number of keys + 1 | none |
| Number of values | none | number of keys |
| Key purpose | used for routing | paired with value |
| Stores values? | No | Yes |
让我们通过一个示例来展示 B-tree 在插入元素时如何增长。为了简化,我们采用 order 为 3 的树来做说明。这就意味着:
- 每个内部节点最多包含 3 个子节点
- 每个内部节点最多包含 2 个键
- 每个内部节点至少包含 2 个子节点
- 每个内部节点至少包含 1 个键
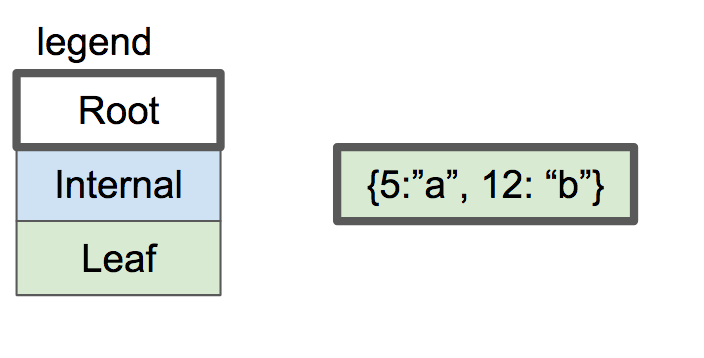
一个空的 B-tree 仅包含一个节点:root 节点(根节点)。根节点从具有零个键/值对的叶节点开始:
 |
如果我们插入几个键/值对,它们将按排序顺序存储在叶节点中。
 |
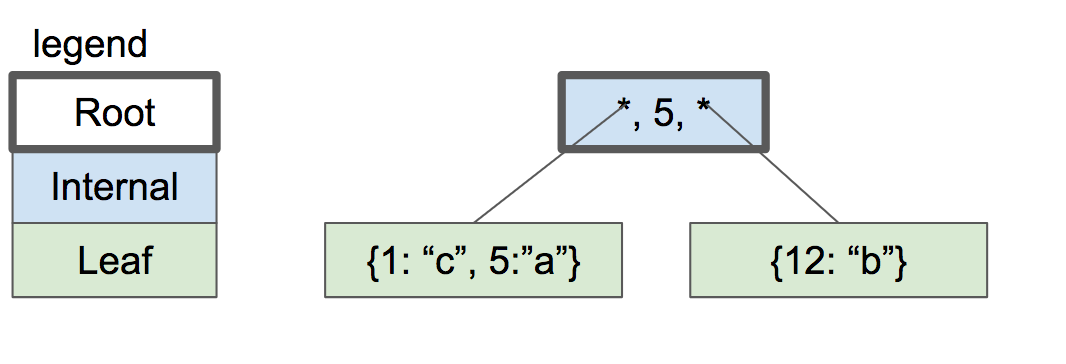
假设叶子节点的容量是两个键/值对。当我们插入另一个时,我们必须拆分叶子节点并将一半键/值对放入每个节点中。两个节点都成为新内部节点的子节点,该内部节点现在将成为根节点。
 |
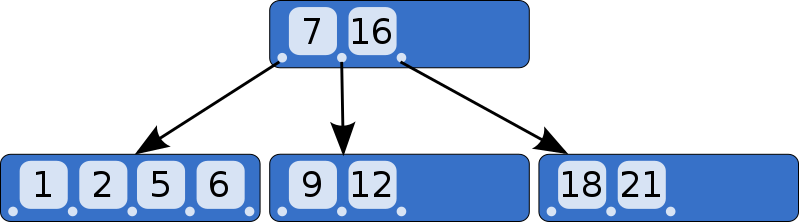
这个内部节点拥有 1 个键和 2 个指向子节点的指针。如果我们想要查找小于或等于 5 的键,我们将从左子节点中查找。如果我们想要查找大于 5 的键,我们将从右子节点中查找。
现在,我们插入键 2。首先,如果存在的话,我们将查找它所在的叶子节点,然后到达左边的叶子节点。该节点已满,因此我们拆分叶子节点并在父节点中创建一个新条目。
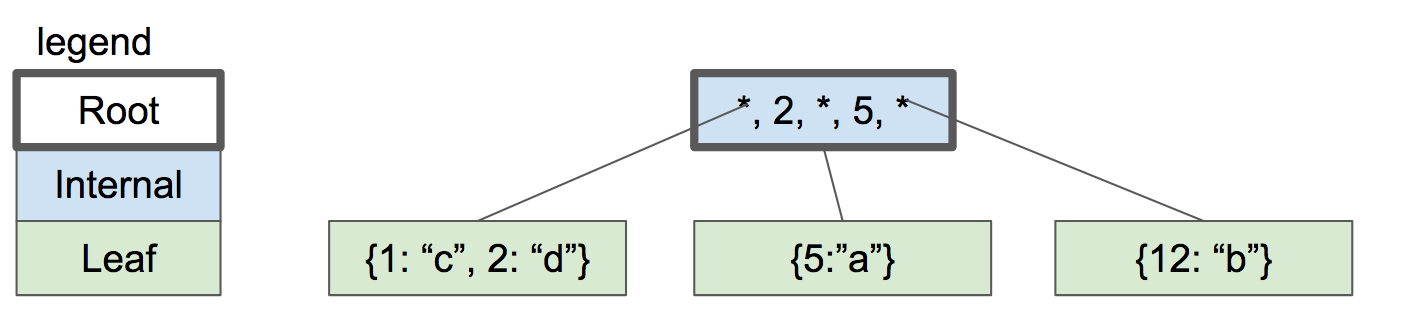 |
让我们继续添加键,18 和 21。我们到了必须再次拆分的地步,但是父节点中没有空间可以容纳另一个键/指针对。
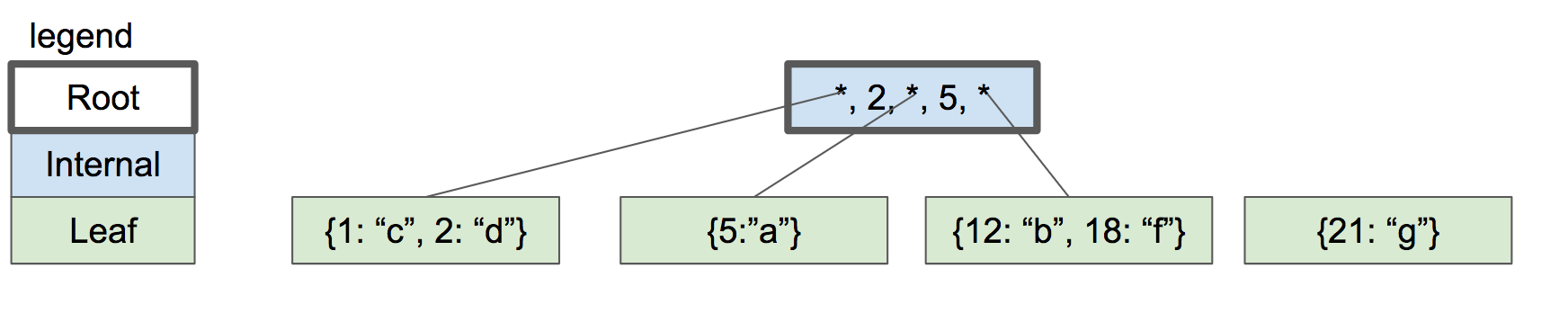 |
解决方案是将根节点分为两个内部节点,然后创建新的根节点作为其父节点。
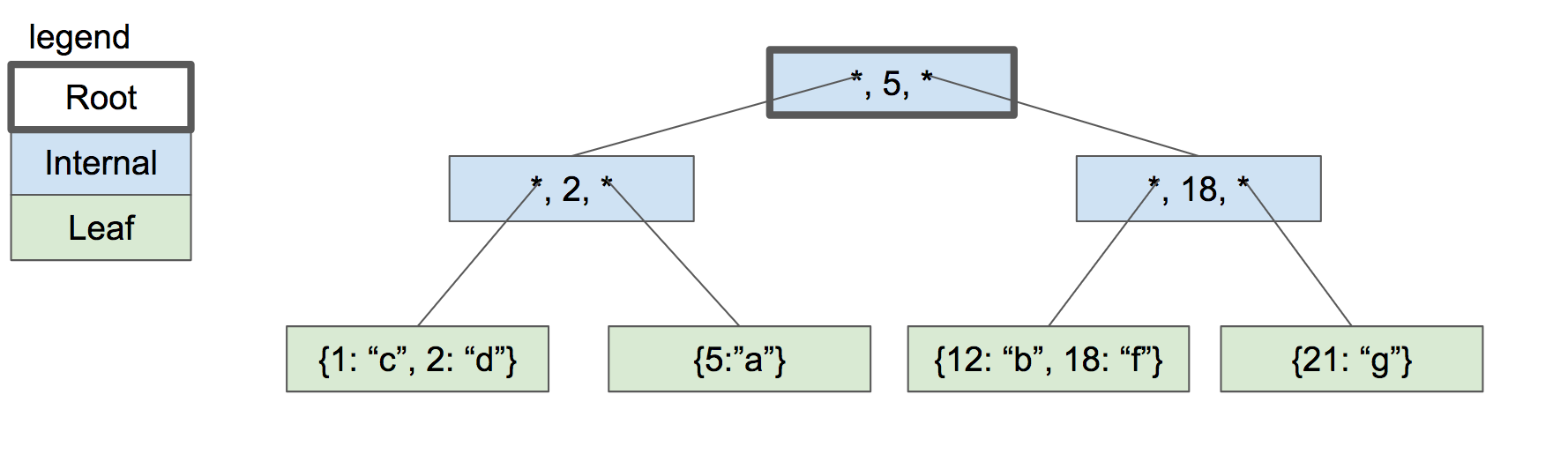 |
树的高度仅在叶子节点分裂的时候才会增加。每个叶子节点的深度都相同,并且键/值对的数量接近相同,因此树保持平衡并且可以快速搜索。
在我们实现插入之前,我将不讨论从树中删除键的讨论。
当我们实现此数据结构时,每个节点将对应一个页面。 根节点将存在于页面 0 中。子指针将仅是包含子节点的页码。
在下一节中,我们将开始实现 btree!