PostgreSQL buffer usage 溢出
今天灿灿(微信公众号:PostgreSQL 学徒)发来一个问题,说是日志中 buffer usage 出现了负数,如下所示。
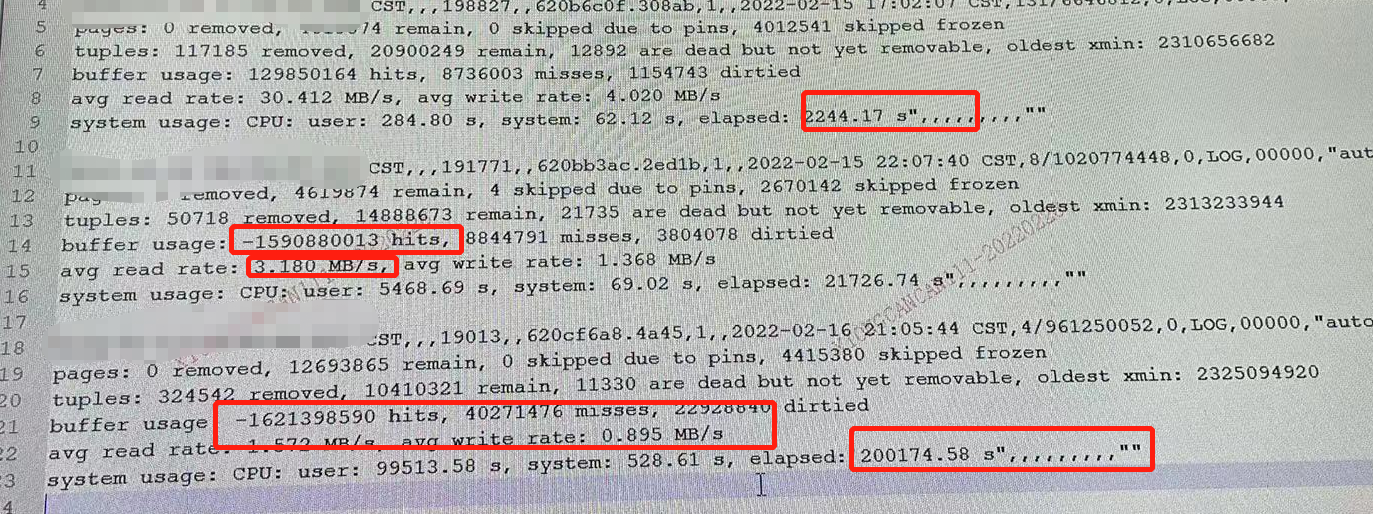
今天灿灿(微信公众号:PostgreSQL 学徒)发来一个问题,说是日志中 buffer usage 出现了负数,如下所示。
最近在做申威平台的兼容时发现一个关于编译器优化的 BUG。第一次遇到编译器优化的问题,因此在这里对其进行简要的记录。
PostgreSQL 提供了自定义参数的功能,您可以使用 SET 或 set_config() 函数来定义参数,本文介绍一下在 PG14(14.1 和 14.2)中引入的关于自定义参数标识符的的问题 BUG #17415。
最近在分析 bug 的时候接触到了 git bisect 这个命令,虽然之前也知道这个命令,但是由于平时用的不多所以没有深入的研究,对它的使用方法也不是很熟悉。其实这个命令使用起来还是非常简单的,本文结合实际情况简要介绍一下 git bisect 的使用方法。
最近在邮件列表中发现 CREATE OR REPLACE VIEW 存在一个 bug,无法更新输出列的 collation。如下所示:
1 | postgres=# CREATE TABLE tbl (info text); |
可以看到在 Collation 列中没有发生改变,而且也没任何提示,只是默默的丢弃了 COLLATE "en_US.utf8",但是在视图的定义中又更新了 Collation,这多少让人有点疑惑。
今天遇到关于私钥格式的问题,需要通过远程连接访问远端的服务器,该服务器是客户给的,然后通过 ssh 的方式访问,然而客户给的私钥是如下形式的:
1 | -----BEGIN OPENSSH PRIVATE KEY----- |
通过 ssh 连接时报无效的格式,Load key "~/.ssh/openssh_id_rsa": invalid format。本文简要记录一下解决方法。
最近看到一个问题,说是在 ExecIndexBuildScanKeys() 函数中的 isorderby 参数在有 ORDER BY 字句时,IndexScan 中的 indexorderby 也为空。例如下面两个查询:
1 | SELECT col FROM table_name ORDER BY index_key op const LIMIT 5; |
这两个查询在执行 ExecIndexBuildScanKeys() 时 IndexScan 结构中的 indexorderby 均为空。然而,IndexScan->indexorderby 的注释为 list of index ORDER BY exprs,即 ORDER BY 语句后面的索引表达式,第一个 SQL 语句明显有 ORDER BY 字句,那么为什么此时的 indexorderby 为空呢?
最近 Robert Haas 提交了一个关于 pg_basebackup 指定备份存储位置的功能,详细信息如下:
commit 3500ccc39b0dadd1068a03938e4b8ff562587ccc
Author: Robert Haas <rhaas@postgresql.org>
Date: Tue Nov 16 15:20:50 2021 -0500
Support base backup targets.
pg_basebackup now has a --target=TARGET[:DETAIL] option. If specfied,
it is sent to the server as the value of the TARGET option to the
BASE_BACKUP command. If DETAIL is included, it is sent as the value of
the new TARGET_DETAIL option to the BASE_BACKUP command. If the
target is anything other than 'client', pg_basebackup assumes that it
will now be the server's job to write the backup in a location somehow
defined by the target, and that it therefore needs to write nothing
locally. However, the server will still send messages to the client
for progress reporting purposes.
On the server side, we now support two additional types of backup
targets. There is a 'blackhole' target, which just throws away the
backup data without doing anything at all with it. Naturally, this
should only be used for testing and debugging purposes, since you will
not actually have a backup when it finishes running. More usefully,
there is also a 'server' target, so you can now use something like
'pg_basebackup -Xnone -t server:/SOME/PATH' to write a backup to some
location on the server. We can extend this to more types of targets
in the future, and might even want to create an extensibility
mechanism for adding new target types.
Since WAL fetching is handled with separate client-side logic, it's
not part of this mechanism; thus, backups with non-default targets
must use -Xnone or -Xfetch.
Patch by me, with a bug fix by Jeevan Ladhe. The patch set of which
this is a part has also had review and/or testing from Tushar Ahuja,
Suraj Kharage, Dipesh Pandit, and Mark Dilger.
Discussion: http://postgr.es/m/CA+TgmoaYZbz0=Yk797aOJwkGJC-LK3iXn+wzzMx7KdwNpZhS5g@mail.gmail.com
PostgreSQL 15 新增了 jsonlog 日志选项,即可以将日志存储为 json 格式,下面是详细的提交信息。
commit dc686681e0799b12c40f44f85fc5bfd7fed4e57f
Author: Michael Paquier <michael@paquier.xyz>
Date: Mon Jan 17 10:16:53 2022 +0900
Introduce log_destination=jsonlog
"jsonlog" is a new value that can be added to log_destination to provide
logs in the JSON format, with its output written to a file, making it
the third type of destination of this kind, after "stderr" and
"csvlog". The format is convenient to feed logs to other applications.
There is also a plugin external to core that provided this feature using
the hook in elog.c, but this had to overwrite the output of "stderr" to
work, so being able to do both at the same time was not possible. The
files generated by this log format are suffixed with ".json", and use
the same rotation policies as the other two formats depending on the
backend configuration.
This takes advantage of the refactoring work done previously in ac7c807,
bed6ed3, 8b76f89 and 2d77d83 for the backend parts, and 72b76f7 for the
TAP tests, making the addition of any new file-based format rather
straight-forward.
The documentation is updated to list all the keys and the values that
can exist in this new format. pg_current_logfile() also required a
refresh for the new option.
Author: Sehrope Sarkuni, Michael Paquier
Reviewed-by: Nathan Bossart, Justin Pryzby
Discussion: https://postgr.es/m/CAH7T-aqswBM6JWe4pDehi1uOiufqe06DJWaU5=X7dDLyqUExHg@mail.gmail.com
最近在浏览邮件列表时发现通过 pg_dump 导出带有行类型的规则导出之后无法导入到数据库中,已确认为 bug,目前已被修复。
commit 43c2175121c829c8591fc5117b725f1f22bfb670
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Thu Jan 13 17:49:25 2022 -0500
Fix ruleutils.c's dumping of whole-row Vars in more contexts.
Commit 7745bc352 intended to ensure that whole-row Vars would be
printed with "::type" decoration in all contexts where plain
"var.*" notation would result in star-expansion, notably in
ROW() and VALUES() constructs. However, it missed the case of
INSERT with a single-row VALUES, as reported by Timur Khanjanov.
Nosing around ruleutils.c, I found a second oversight: the
code for RowCompareExpr generates ROW() notation without benefit
of an actual RowExpr, and naturally it wasn't in sync :-(.
(The code for FieldStore also does this, but we don't expect that
to generate strictly parsable SQL anyway, so I left it alone.)
Back-patch to all supported branches.
Discussion: https://postgr.es/m/efaba6f9-4190-56be-8ff2-7a1674f9194f@intrans.baku.az